En ciencias de la comptucacion y análisis numérico el pseudocódigo (o falso lengua) es una descripción de un algoritmo informático de programación de alto nivel compacto e informal que utiliza las convenciones estructurales de un lenguaje de programaciónverdadero, pero que está diseñado para la lectura humana en lugar de la lectura en máquina, y con independencia de cualquier otro lenguaje de programación. Normalmente, el pseudocódigo omite detalles que no son esenciales para la comprensión humana del algoritmo, tales como declaraciones de variables, código específico del sistema y algunas subrutinas. El lenguaje de programación se complementa, donde sea conveniente, con descripciones detalladas en lenguaje natural, o con notación matemática compacta. Se utiliza pseudocódigo pues este es más fácil de entender para las personas que el código de lenguaje de programación convencional, ya que es una descripción eficiente y con un entorno independiente de los principios fundamentales de un algoritmo. Se utiliza comúnmente en los libros de texto y publicaciones científicas que se documentan varios algoritmos, y también en la planificación del desarrollo de programas informáticos, para esbozar la estructura del programa antes de realizar la codificación efectivamente. No existe una sintaxis estándar para el pseudocódigo, aunque los cuatro programas que manejan pseudocódigo tengan su sintaxis propia. Aunque sea parecido, el pseudocódigo no debe confundirse con los programas esqueleto que incluyen código ficticio, que pueden sercompilados sin errores. Aunque los diagramas de flujo y UML sean más amplios en el papel, pueden ser considerados como una alternativa gráfica al pseudocódigo.
Las principales características de este lenguaje son:
- Se puede ejecutar en un ordenador (con un IDE como por ejemplo SLE, LPP, PilatoX o PSeInt)
- Es una forma de representación sencilla de utilizar y de manipular.
- Facilita el paso del programa al lenguaje de programación.
- Es independiente del lenguaje de programación que se vaya a utilizar.
- Es un método que facilita la programación y solución al algoritmo del programa.
Todo documento en pseudocódigo debe permitir la descripción de:
- Instrucciones primitivas.
- Instrucciones de proceso....
- Instrucciones de control.
- Instrucciones compuestas.
- Instrucciones de descripción.
Estructura a seguir en su realización:
-
Cabecera.
- Programa.
- Módulo.
- Tipos de datos.
- Constantes.
- Variables.
- Cuerpo.
- Inicio.
- Instrucciones.
- Fin.
DEFINICIÓN DE ALGORITMO
La definición de datos se da por supuesta, sobre todo en las variables sencillas, si se emplea formaciones: pilas, colas, vectores o registros, se pueden definir en la cabecera del algoritmo, y naturalmente cuando empleemos el pseudocódigo para definir estructuras de datos, esta parte la desarrollaremos adecuadamente.
Cada autor usa su propio pseudocódigo con sus respectivas convenciones. Por ejemplo, la instrucción "reemplace el valor de la variable  por el valor de la variable
por el valor de la variable  " puede ser representado como:
" puede ser representado como:
- asigne a
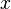 el valor de
el valor de 
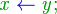


Las operaciones aritméticas se representan de la forma usual en matemáticas.

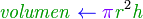



Estructuras selectivas
Las instrucciones selectivas representan instrucciones que pueden o no ejecutarse, según el cumplimiento de una condición.



La condición es una expresión booleana. Instrucciones es ejecutada sólo si la condición es verdadera.
[editar]
Selectiva doble (alternativa)
La instrucción alternativa realiza una instrucción de dos posibles, según el cumplimiento de una condición.
-


La condición es una variable booleana o una función reducible a booleana (lógica, Verdadero/Falso). Si esta condición es cierta se ejecuta Instrucciones1, si no es así, entonces se ejecuta Instrucciones2.
ALGORITMOS
En matemáticas, ciencias de la computación y disciplinas relacionadas, un algoritmo (del griego y latín, dixit algorithmus y este a su vez del matemático persa Al-Juarismi1 ) es un conjunto preescrito de instrucciones o reglas bien definidas, ordenadas y finitas que permite realizar una actividad mediante pasos sucesivos que no generen dudas a quien deba realizar dicha actividad.2 Dados un estado inicial y una entrada, siguiendo los pasos sucesivos se llega a un estado final y se obtiene una solución. Los algoritmos son el objeto de estudio de la algoritmia.1
En la vida cotidiana, se emplean algoritmos frecuentemente para resolver problemas. Algunos ejemplos son los manuales de usuario, que muestran algoritmos para usar un aparato, o las instrucciones que recibe un trabajador por parte de su patrón. Algunos ejemplos en matemática son el algoritmo de la división para calcular el cociente de dos números, el algoritmo de Euclides para obtener el máximo común divisor de dos enterospositivos, o el método de Gauss para resolver un sistema lineal de ecuaciones.
Los algoritmos de ordenamiento se pueden clasificar de las siguientes maneras:
-
La más común es clasificar según el lugar donde se realice la ordenación
- Algoritmos de ordenamiento interno: en la memoria del ordenador.
- Algoritmos de ordenamiento externo: en un lugar externo como un disco duro.
-
Por el tiempo que tardan en realizar la ordenación, dadas entradas ya ordenadas o inversamente ordenadas:
- Algoritmos de ordenación natural: Tarda lo mínimo posible cuando la entrada está ordenada.
- Algoritmos de ordenación no natural: Tarda lo mínimo posible cuando la entrada está inversamente ordenada.
- Por estabilidad: un ordenamiento estable mantiene el orden relativo que tenían originalmente los elementos con claves iguales. Por ejemplo, si una lista ordenada por fecha se reordena en orden alfabético con un algoritmo estable, todos los elementos cuya clave alfabética sea la misma quedarán en orden de fecha. Otro caso sería cuando no interesan las mayúsculas y minúsculas, pero se quiere que si una clave aBC estaba antes que AbC, en el resultado ambas claves aparezcan juntas y en el orden original: aBC, AbC. Cuando los elementos son indistinguibles (porque cada elemento se ordena por la clave completa) la estabilidad no interesa. Los algoritmos de ordenamiento que no son estables se pueden implementar para que sí lo sean. Una manera de hacer esto es modificar artificialmente la clave de ordenamiento de modo que la posición original en la lista participe del ordenamiento en caso de coincidencia.
Los algoritmos se distinguen por las siguientes características:
- Complejidad computacional (peor caso, caso promedio y mejor caso) en términos de n, el tamaño de la lista o arreglo. Para esto se usa el concepto de orden de una función y se usa la notación O(n). El mejor comportamiento para ordenar (si no se aprovecha la estructura de las claves) es O(n log n). Los algoritmos más simples son cuadráticos, es decir O(n²). Los algoritmos que aprovechan la estructura de las claves de ordenamiento (p. ej. bucket sort) pueden ordenar en O(kn) donde k es el tamaño del espacio de claves. Como dicho tamaño es conocido a priori, se puede decir que estos algoritmos tienen un desempeño lineal, es decir O(n).
- Uso de memoria y otros recursos computacionales. También se usa la notación O(n)
ESTABILIDAD
Los algoritmos de ordenamiento estable mantienen un relativo preorden total. Esto significa que un algoritmo es estable solo cuando hay dos registros R y S con la misma clave y con R apareciendo antes que S en la lista original.
Cuando elementos iguales (indistinguibles entre sí), como números enteros, o más generalmente, cualquier tipo de dato en donde el elemento entero es la clave, la estabilidad no es un problema. De todas formas, se asume que los siguientes pares de números están por ser ordenados por su primer componente:
(4, 1) (3, 7) (3, 1) (5, 6)
En este caso, dos resultados diferentes son posibles, uno de los cuales mantiene un orden relativo de registros con claves iguales, y una en la que no:
(3, 7) (3, 1) (4, 1) (5, 6) (orden mantenido)
(3, 1) (3, 7) (4, 1) (5, 6) (orden cambiado)
Los algoritmos de ordenamiento inestable pueden cambiar el orden relativo de registros con claves iguales, pero los algoritmos estables nunca lo hacen. Los algoritmos inestables pueden ser implementados especialmente para ser estables. Una forma de hacerlo es extender artificialmente el cotejamiento de claves, para que las comparaciones entre dos objetos con claves iguales sean decididas usando el orden de las entradas original. Recordar este orden entre dos objetos con claves iguales es una solución poco práctica, ya que generalmente acarrea tener almacenamiento adicional.
Ordenar según una clave primaria, secundaria, terciara, etc., puede ser realizado utilizando cualquier método de ordenamiento, tomando todas las claves en consideración (en otras palabras, usando una sola clave compuesta). Si un método de ordenamiento es estable, es posible ordenar múltiples ítems, cada vez con una clave distinta. En este caso, las claves necesitan estar aplicadas en orden de aumentar la prioridad.
Ejemplo: ordenar pares de números, usando ambos valores
(4, 1) (3, 7) (3, 1) (4, 6) (original)
(4, 1) (3, 1) (4, 6) (3, 7) (después de ser ordenado por el segundo valor)
(3, 1) (3, 7) (4, 1) (4, 6) (después de ser ordenado por el primer valor)
Por otro lado:
(3, 7) (3, 1) (4, 1) (4, 6) (después de ser ordenado por el primer valor)
(3, 1) (4, 1) (4, 6) (3, 7) (después de ser ordenando por el segundo valor,
el orden por el primer valor es perturbado)
Algunos algoritmos de ordenamiento agrupados según estabilidad tomando en cuenta la complejidad computacional.
Estables Nombre traducido Nombre original Complejidad Memoria Método Ordenamiento de burbuja Bubblesort O(n²) O(1) Intercambio Ordenamiento de burbuja bidireccional Cocktail sort O(n²) O(1) Intercambio Ordenamiento por inserción Insertion sort O(n²) O(1) Inserción Ordenamiento por casilleros Bucket sort O(n) O(n) No comparativo Ordenamiento por cuentas Counting sort O(n+k) O(n+k) No comparativo Ordenamiento por mezcla Merge sort O(n log n) O(n) Mezcla Ordenamiento con árbol binario Binary tree sort O(n log n) O(n) Inserción Pigeonhole sort O(n+k) O(k) Ordenamiento Radix Radix sort O(nk) O(n) No comparativo Distribution sort O(n³) versión recursiva O(n²) Gnome sort O(n²) Inestables Nombre traducido Nombre original Complejidad Memoria Método Ordenamiento Shell Shell sort O(n1.25) O(1) Inserción Comb sort O(n log n) O(1) Intercambio Ordenamiento por selección Selection sort O(n²) O(1) Selección Ordenamiento por montículos Heapsort O(n log n) O(1) Selección Smoothsort O(n log n) O(1) Selección Ordenamiento rápido Quicksort Promedio: O(n log n),
peor caso: O(n²) O(log n) Partición Several Unique Sort Promedio: O(n u),
peor caso: O(n²);
u=n; u = número único de registros Cuestionables, imprácticos Nombre traducido Nombre original Complejidad Memoria Método Bogosort O(n × n!), peor: no termina Pancake sorting O(n), excepto en
máquinas de Von Neumann Randomsort Promedio: O(n!) Peor: No termina
Cabecera.
- Programa.
- Módulo.
- Tipos de datos.
- Constantes.
- Variables.
- Inicio.
- Instrucciones.
- Fin.
Cada autor usa su propio pseudocódigo con sus respectivas convenciones. Por ejemplo, la instrucción "reemplace el valor de la variable por el valor de la variable " puede ser representado como:
por el valor de la variable " puede ser representado como:- asigne a el valor de
Las operaciones aritméticas se representan de la forma usual en matemáticas.
Estructuras selectivas
Las instrucciones selectivas representan instrucciones que pueden o no ejecutarse, según el cumplimiento de una condición.

La condición es una expresión booleana. Instrucciones es ejecutada sólo si la condición es verdadera.
[editar]
Selectiva doble (alternativa)
La instrucción alternativa realiza una instrucción de dos posibles, según el cumplimiento de una condición.

La condición es una variable booleana o una función reducible a booleana (lógica, Verdadero/Falso). Si esta condición es cierta se ejecuta Instrucciones1, si no es así, entonces se ejecuta Instrucciones2.
ALGORITMOS
En matemáticas, ciencias de la computación y disciplinas relacionadas, un algoritmo (del griego y latín, dixit algorithmus y este a su vez del matemático persa Al-Juarismi1 ) es un conjunto preescrito de instrucciones o reglas bien definidas, ordenadas y finitas que permite realizar una actividad mediante pasos sucesivos que no generen dudas a quien deba realizar dicha actividad.2 Dados un estado inicial y una entrada, siguiendo los pasos sucesivos se llega a un estado final y se obtiene una solución. Los algoritmos son el objeto de estudio de la algoritmia.1
En la vida cotidiana, se emplean algoritmos frecuentemente para resolver problemas. Algunos ejemplos son los manuales de usuario, que muestran algoritmos para usar un aparato, o las instrucciones que recibe un trabajador por parte de su patrón. Algunos ejemplos en matemática son el algoritmo de la división para calcular el cociente de dos números, el algoritmo de Euclides para obtener el máximo común divisor de dos enterospositivos, o el método de Gauss para resolver un sistema lineal de ecuaciones.
Los algoritmos de ordenamiento se pueden clasificar de las siguientes maneras:
- La más común es clasificar según el lugar donde se realice la ordenación
- Algoritmos de ordenamiento interno: en la memoria del ordenador.
- Algoritmos de ordenamiento externo: en un lugar externo como un disco duro.
- Por el tiempo que tardan en realizar la ordenación, dadas entradas ya ordenadas o inversamente ordenadas:
- Algoritmos de ordenación natural: Tarda lo mínimo posible cuando la entrada está ordenada.
- Algoritmos de ordenación no natural: Tarda lo mínimo posible cuando la entrada está inversamente ordenada.
- Por estabilidad: un ordenamiento estable mantiene el orden relativo que tenían originalmente los elementos con claves iguales. Por ejemplo, si una lista ordenada por fecha se reordena en orden alfabético con un algoritmo estable, todos los elementos cuya clave alfabética sea la misma quedarán en orden de fecha. Otro caso sería cuando no interesan las mayúsculas y minúsculas, pero se quiere que si una clave aBC estaba antes que AbC, en el resultado ambas claves aparezcan juntas y en el orden original: aBC, AbC. Cuando los elementos son indistinguibles (porque cada elemento se ordena por la clave completa) la estabilidad no interesa. Los algoritmos de ordenamiento que no son estables se pueden implementar para que sí lo sean. Una manera de hacer esto es modificar artificialmente la clave de ordenamiento de modo que la posición original en la lista participe del ordenamiento en caso de coincidencia.
Los algoritmos se distinguen por las siguientes características:
- Complejidad computacional (peor caso, caso promedio y mejor caso) en términos de n, el tamaño de la lista o arreglo. Para esto se usa el concepto de orden de una función y se usa la notación O(n). El mejor comportamiento para ordenar (si no se aprovecha la estructura de las claves) es O(n log n). Los algoritmos más simples son cuadráticos, es decir O(n²). Los algoritmos que aprovechan la estructura de las claves de ordenamiento (p. ej. bucket sort) pueden ordenar en O(kn) donde k es el tamaño del espacio de claves. Como dicho tamaño es conocido a priori, se puede decir que estos algoritmos tienen un desempeño lineal, es decir O(n).
- Uso de memoria y otros recursos computacionales. También se usa la notación O(n)
ESTABILIDAD
Los algoritmos de ordenamiento estable mantienen un relativo preorden total. Esto significa que un algoritmo es estable solo cuando hay dos registros R y S con la misma clave y con R apareciendo antes que S en la lista original.
Cuando elementos iguales (indistinguibles entre sí), como números enteros, o más generalmente, cualquier tipo de dato en donde el elemento entero es la clave, la estabilidad no es un problema. De todas formas, se asume que los siguientes pares de números están por ser ordenados por su primer componente:
(4, 1) (3, 7) (3, 1) (5, 6)
En este caso, dos resultados diferentes son posibles, uno de los cuales mantiene un orden relativo de registros con claves iguales, y una en la que no:
(3, 7) (3, 1) (4, 1) (5, 6) (orden mantenido)(3, 1) (3, 7) (4, 1) (5, 6) (orden cambiado)
Los algoritmos de ordenamiento inestable pueden cambiar el orden relativo de registros con claves iguales, pero los algoritmos estables nunca lo hacen. Los algoritmos inestables pueden ser implementados especialmente para ser estables. Una forma de hacerlo es extender artificialmente el cotejamiento de claves, para que las comparaciones entre dos objetos con claves iguales sean decididas usando el orden de las entradas original. Recordar este orden entre dos objetos con claves iguales es una solución poco práctica, ya que generalmente acarrea tener almacenamiento adicional.
Ordenar según una clave primaria, secundaria, terciara, etc., puede ser realizado utilizando cualquier método de ordenamiento, tomando todas las claves en consideración (en otras palabras, usando una sola clave compuesta). Si un método de ordenamiento es estable, es posible ordenar múltiples ítems, cada vez con una clave distinta. En este caso, las claves necesitan estar aplicadas en orden de aumentar la prioridad.
Ejemplo: ordenar pares de números, usando ambos valores
(4, 1) (3, 7) (3, 1) (4, 6) (original)
(4, 1) (3, 1) (4, 6) (3, 7) (después de ser ordenado por el segundo valor)(3, 1) (3, 7) (4, 1) (4, 6) (después de ser ordenado por el primer valor)
Por otro lado:
(3, 7) (3, 1) (4, 1) (4, 6) (después de ser ordenado por el primer valor)(3, 1) (4, 1) (4, 6) (3, 7) (después de ser ordenando por el segundo valor,el orden por el primer valor es perturbado)
Algunos algoritmos de ordenamiento agrupados según estabilidad tomando en cuenta la complejidad computacional.
| Estables | ||||
| Nombre traducido | Nombre original | Complejidad | Memoria | Método |
| Ordenamiento de burbuja | Bubblesort | O(n²) | O(1) | Intercambio |
| Ordenamiento de burbuja bidireccional | Cocktail sort | O(n²) | O(1) | Intercambio |
| Ordenamiento por inserción | Insertion sort | O(n²) | O(1) | Inserción |
| Ordenamiento por casilleros | Bucket sort | O(n) | O(n) | No comparativo |
| Ordenamiento por cuentas | Counting sort | O(n+k) | O(n+k) | No comparativo |
| Ordenamiento por mezcla | Merge sort | O(n log n) | O(n) | Mezcla |
| Ordenamiento con árbol binario | Binary tree sort | O(n log n) | O(n) | Inserción |
| Pigeonhole sort | O(n+k) | O(k) | ||
| Ordenamiento Radix | Radix sort | O(nk) | O(n) | No comparativo |
| Distribution sort | O(n³) versión recursiva | O(n²) | ||
| Gnome sort | O(n²) | |||
| Inestables | ||||
| Nombre traducido | Nombre original | Complejidad | Memoria | Método |
| Ordenamiento Shell | Shell sort | O(n1.25) | O(1) | Inserción |
| Comb sort | O(n log n) | O(1) | Intercambio | |
| Ordenamiento por selección | Selection sort | O(n²) | O(1) | Selección |
| Ordenamiento por montículos | Heapsort | O(n log n) | O(1) | Selección |
| Smoothsort | O(n log n) | O(1) | Selección | |
| Ordenamiento rápido | Quicksort | Promedio: O(n log n), peor caso: O(n²) | O(log n) | Partición |
| Several Unique Sort | Promedio: O(n u), peor caso: O(n²); u=n; u = número único de registros | |||
| Cuestionables, imprácticos | ||||
| Nombre traducido | Nombre original | Complejidad | Memoria | Método |
| Bogosort | O(n × n!), peor: no termina | |||
| Pancake sorting | O(n), excepto en máquinas de Von Neumann | |||
| Randomsort | Promedio: O(n!) Peor: No termina | |||